Digital operations
Minimize the impact of IT service disruptions and reduce unplanned work.

Keep IT services running and deliver great products
The Everbridge digital operations platform monitors performance across all systems to strengthen security and automate IT workflows to enable teams to work quickly and confidently. Predict disruptions based on thousands of data sources and signal and alert the right people. DevOps, SREs, IT, and Operations teams use Everbridge to maintain robust services for everyone.
Monitor risk and performance across all systems:
- Integrate development, project management, security, and customer success tools across the organization
- Combine signals from multiple monitoring tools into relevant, contextual actions
- Quickly find the root cause of performance issues before they impact customers
Automate IT incident response management:
- Initiate proactive incident management workflows and alerts
- Orchestrate rapid response to critical events
- Alert the right people to threats
- Solve active issues with AI-powered incident matching from historical fixes
Low-code, intelligent workflows for operations teams:
- Use templates or build workflows from an intuitive UI
- Automate on-call scheduling
- Eliminate complex refactoring projects and unwanted dependencies

Identify incidents and address issues quickly
Everbridge Digital Operations Platform allows teams to open fewer tickets and spend less time reinventing iterative resolutions, leading to faster Mean Time to Repair (MTTR)—so impacted services get resolved before users become aware. Less time spent on incidents means more time for innovation.
Build automated, intelligent workflows
Automate time-sensitive tasks, proactively manage issues, and enable faster deployment.
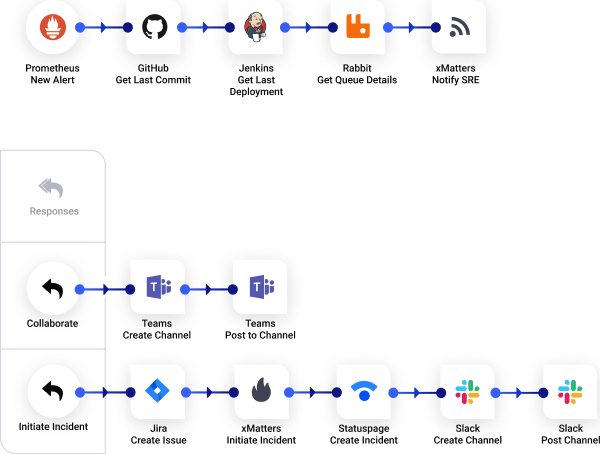

Protect the customer experience
Deliver remarkable products and services at scale by automating the workflows that keep customers happy. Proactively automate resolutions through coordinated, templated actions across all communication channels.
Analyze and monitor performance
Surface priority issues and proactively respond with AI-powered signal enrichment, service intelligence, change telemetry, and observability. The Everbridge critical event management platform logs every event to create a secure audit trail and a clear understanding of what went wrong.

Maximize uptime and productivity
Maintain strong application and infrastructure performance with automated operations workflows. Everbridge offers a single, collaborative view of reliability that Security, IT, Product, and Operations can use to avoid outages, meet SLAs, and deliver products quickly.
DevOps & SREs
Reduce bottlenecks and work confidently, knowing issues will have minimal impact on service reliability.
IT operations
Integrate disparate tools and data sources, rapidly determine root cause, and reduce MTTR.
Stakeholder collaboration
Manage ChatOps and situation reporting, triage crises from a single dashboard, and connect over any device.
More than 6,500 global customers use Everbridge



“By implementing Everbridge xMatters in our notification workflow, we’ve been able to quickly and reliably engage our physicians, which leads to faster evaluation and treatment for our acute stroke patients.”
Katherine Repko
TeleHealth Operations Initiatives Manager, Intermountain Healthcare

Gordon Food Service achieves less downtime and increased efficiencies with Everbridge xMatters
Gordon Food Service has seen a notable ROI by relying on Everbridge xMatters. Less downtime and increased efficiencies are just two benefits of the solution.
Related products
xMatters
Automate incident management processes to rapidly deliver digital products at scale, and ensure infrastructure, workflows, and application downtime are minimized.
Crisis Management
Coordinate crisis response via a unified platform for seamless command and control during unexpected scenarios.
SnapComms
Deliver high-impact multi-channel integrated internal communications to reach and engage employees.
Related resources

Awareness, adaptability, and AIOps
When you’re faced with constantly changing conditions, situational awareness is key for driving your teams’ reaction to these changes. Your systems need to be adaptable and responsive.

Using AIOps for better adaptive incident management
An effective incident management strategy is crucial for any business, especially those offering consumer-facing digital services. To minimize the reach and severity of incidents, your response needs to be swift and effective.

Service Intelligence
Revolutionize your response to IT disruptions by dramatically improving resolution times, root-cause analyses outcomes, and value stream delivery for digital services.