Slik hjelper vi
Everbridge digitaliserer organisasjonsmessig robusthet i stor skala og gjør det mulig for kunder å beskytte personell og eiendeler med en integrert pakke av løsninger for krisehåndtering.
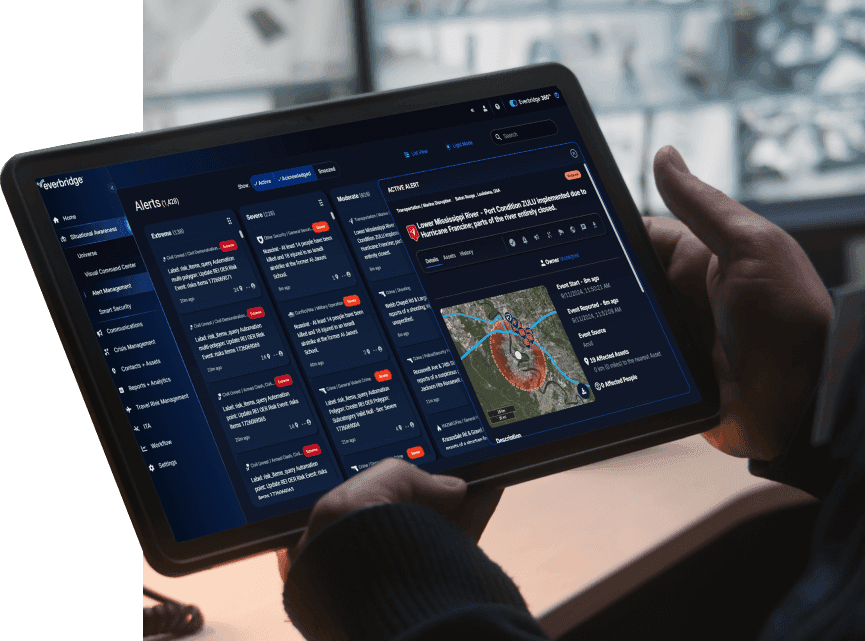
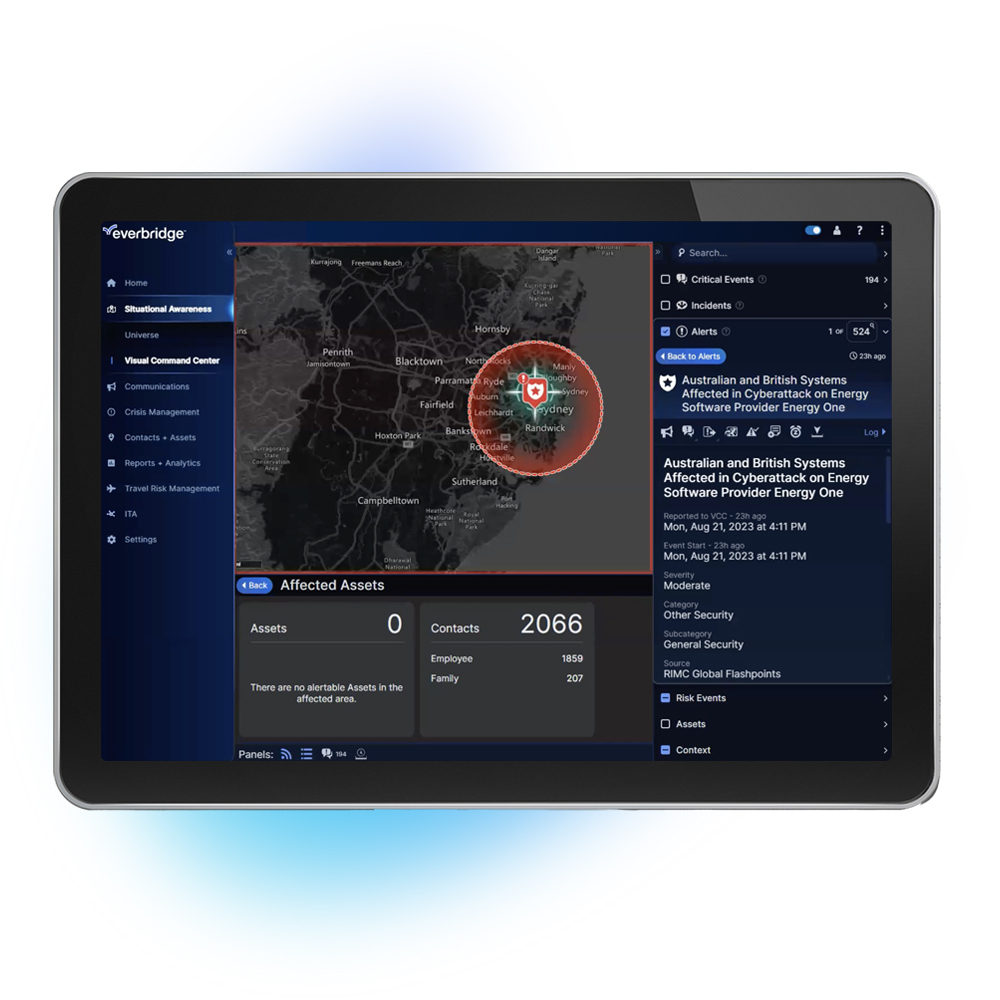
Everbridge 360™ gjør organisasjoner i stand til å forutse, avhjelpe, gripe tak i og komme seg etter kriser. Den enhetlige plattformen vår digitaliserer organisasjonsmessig robusthet ved å kombinere intelligent automatisering med bransjens mest omfattende risikodata for å holde folk trygge og organisasjoner i drift i tråd med varemerket Keep People Safe and Organizations Running™.




Everbridge 360™ representerer den hvileløse satsningen vår på å tilby kundene våre det mest omfattende og enhetlige grensesnittet for å håndtere kriser på tvers av én enkeltplattform så dere får vite tidligere, kan reagere hurtigere og forbedre kontinuerlig.
Håndter mer effektivt kriser, begrens kommunikasjonsforsinkelser til et minimum og forbedre samlet organisasjonsmessig robusthet gjennom bransjens mest avanserte og enhetlige dashbord.
Everbridge digitaliserer organisasjonsmessig robusthet i stor skala og gjør det mulig for kunder å beskytte personell og eiendeler med en integrert pakke av løsninger for krisehåndtering.

Som en formålsparagrafdreven organisasjon forplikter Everbridge seg til å oppfylle ansvarsplikten vår, veilede kundene våre gjennom kritiske utfordringer og påvirke verden positivt. Kundene våre omfatter foretak på Fortune 1000-listen samt ledere i bransjer som finanstjenester, helse, teknologi og telekommunikasjon, energi og offentlige tjenester, transport, detaljhandel og netthandel, offentlig sektor, industri og utdanning.




«Med krisehåndteringsmodulen er vi i stand til å raskt vurdere situasjonen, aktivere den riktige planen og sikre at de rette tiltakene blir fattet for å best beskytte folkene og avdelingene våre.»
Avtal din personlige live-demo eller kontakt oss: +47 95 25 26 10